Most AI scribes tell you their notes are "accurate."
At Clinpax, we haven't just built an ambient scribe — we subject every aspect of our output to the kind of rigorous, reproducible evaluation you'd expect from a peer-reviewed study. Because when a note becomes part of a patient's medical record, "good enough" isn't good enough.
Here's how we think about note quality — and why it's harder than most people realize.
The problem most people don't talk about: where errors actually come from
Clinical note generation isn't a single step. It's a pipeline — and errors can enter at every stage. Understanding where they originate is the first step toward eliminating them.
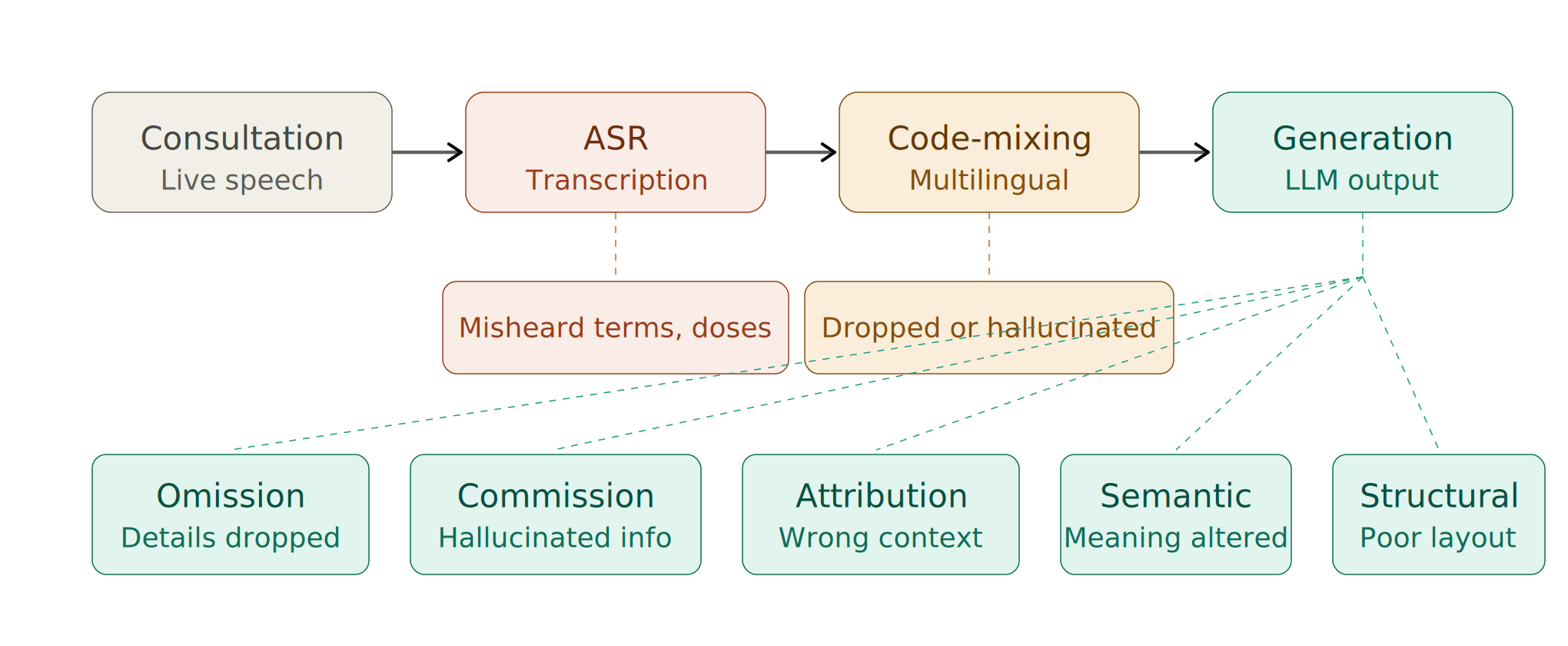
We break the error landscape into distinct categories:
1. ASR (Speech Recognition) Errors
Before a note can be written, the conversation must be transcribed. Automatic Speech Recognition is imperfect — especially in real clinical settings with background noise, rapid speech, medical terminology, and overlapping dialogue. A misheard drug name or dosage at this stage cascades downstream into the final note.
2. Code-Mixing and Multilingual Errors
This is a challenge most global AI scribes simply ignore. In many clinical contexts — particularly across South Asia, the Middle East, and multilingual communities worldwide — doctors and patients switch between languages mid-sentence. A single consultation might flow between English, Arabic, Hindi, or Urdu. Standard ASR models are not designed for this. They either drop the non-English segments entirely or hallucinate incorrect transcriptions. At Clinpax, we've built our pipeline specifically to handle code-mixed speech, because that's the reality of clinical practice for millions of consultations every day.
3. Note-Level Errors: The Taxonomy That Matters
Even with a perfect transcript, the note generation step introduces its own failure modes. We evaluate notes against a formal error taxonomy:
Omission — Clinically relevant information from the conversation is missing from the note. A mentioned allergy, a reported symptom, a discussed medication — silently dropped.
Commission — The note contains information that was never stated in the consultation. The model "hallucinates" a finding, a diagnosis, or a detail that doesn't exist in the source conversation. This is arguably the most dangerous error class in clinical AI.
Incorrect Attribution — Information is present but assigned to the wrong context. A symptom described by the patient gets recorded under a different body system, or a past history item appears as a current complaint.
Semantic Distortion — The meaning is subtly altered. "Occasional mild headaches" becomes "chronic headaches." The words are close; the clinical implication is not.
Structural Errors — Information is present but poorly organized — findings in the wrong SOAP section, assessment mixed with subjective history, plan items buried in the narrative.
Understanding this taxonomy allows us to measure quality with precision and improve systematically.
Our evaluation methodology
We don't evaluate notes with anecdotes or cherry-picked examples. Here's what we actually do:
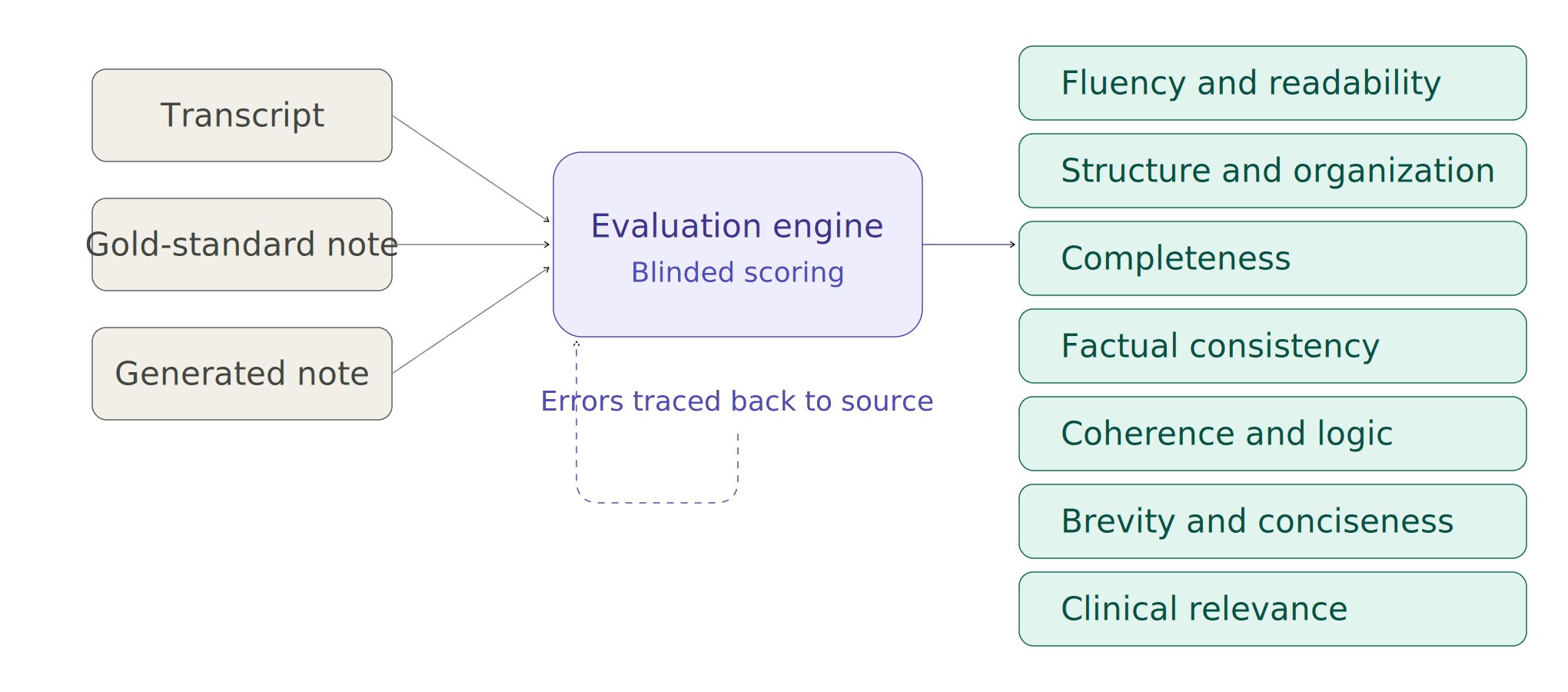
Real benchmark data. We test against doctor–patient consultation transcripts paired with professionally written gold-standard clinical notes. This means our benchmark reflects the messiness, ambiguity, and complexity of actual clinical encounters — not idealized demos.
Seven-dimensional scoring. Every generated note is evaluated across seven criteria that collectively define what a high-quality clinical note looks like:
→ Fluency & Readability — Is the note written in clear, natural clinical language?
→ Structure & Organization — Does it follow a logical, familiar clinical format (SOAP)?
→ Completeness — Are all clinically important details from the conversation captured?
→ Factual Consistency — Does the note accurately reflect what was actually said?
→ Coherence & Logic — Does the note flow in a clinically meaningful way?
→ Brevity & Conciseness — Is the note free of redundant or unnecessary information?
→ Clinical Relevance — Does it focus on what matters for patient care?
Each dimension is scored on a standardized scale.
Independent, blinded evaluation. To remove bias and scale evaluation, we have built a validated evaluation engine. For every consultation, this engine compares three inputs: the original transcript, the gold-standard reference note, and the generated note. It scores blindly across all seven dimensions.
Why we do this — and why it matters
Most ambient scribes in the market today have never published how they evaluate quality. Some rely on internal reviews. Some cite customer satisfaction. Some don't evaluate systematically at all.
We chose a different path — not because it's easy, but because clinical documentation directly impacts patient safety, billing accuracy, medicolegal integrity, and continuity of care. The stakes demand rigor.
When we find errors in our system, we don't just fix them — we categorize them, trace them back to their source (ASR? code-mixing? generation?), and close the loop. That's how you build a system that gets better with every consultation.
The team behind the methodology
This isn't a side project. Our evaluation framework was designed and is continuously refined by a team of PhDs and researchers spanning Computer Science, Artificial Intelligence, Natural Language Processing, Speech Processing, and Clinical Informatics. We bring together deep expertise in multilingual NLP, medical knowledge representation, and rigorous experimental design — the same standards you'd expect from a top-tier research lab, applied to a product used by clinicians every day.
We believe the companies that will earn long-term trust in clinical AI are the ones willing to show their work. This is us showing ours.
If you're evaluating AI scribes for your practice or health system, ask one question: can they explain exactly how they measure quality?
We can. And we're happy to walk you through it.